




In this article, We'll mainly focus on various distributed locking mechanisms and implementation. and We will also explore the different types of locks in databases and how to prevent conflicts to ensure data consistency.
Introduction
In a distributed environment, it is not possible to implement pessimistic and optimistic lock configurations without acquiring locks. Locking mechanisms play a vital role in achieving this goal. And this will include pessimistic and optimistic locks.
What I mean by the distributed environment is, when multiple nodes or machines are involved, Locking is essential to ensure data consistency and prevent conflicts.
Pessimistic Locking
In terms of pessimistic is something worst going to happen, Imagine you have a book that others might want to read. With pessimistic locking, you put a lock on the book and hold onto the key while you're reading it. This ensures that no one else can access the book until you're done. It can limit concurrency because others have to wait for the lock to be released.
Book resultBook = entityManager.find(Book.class, bookId);
entityManager.lock(resultBook , LockModeType.PESSIMISTIC_WRITE);
Optimistic Locking
In terms of optimistic is hoping that something bad not going to happen, Optimistic locking, on the other hand, is like borrowing a book from a library without putting a lock on it. You take the book, assuming that conflicts are rare and others won't try to modify it while you're reading. Before returning the book, you check if anyone else made changes. If no conflicts occurred, you update the book and return it. However, if conflicts are detected, you handle them based on some strategy, like merging changes or notifying users. Optimistic locking allows for concurrent access, improving performance, but it requires conflict detection and resolution mechanisms.
entityManager.find(Book.class, bookId, LockModeType.OPTIMISTIC);
Let's understand in detail with a real-time example,
In the above example, We have data table with columns(ID, DATA, VERSION). Here we are gonna update the specific row(ID: 3) concurrently.
In Optimistic Lock, Person 1 going to read the record and update the data, At the same time Person 2 also trying to update the same data. Here, person 2 updated the data**(3, 28, 2)** before person 1. So there is no conflicts. Now data table will be like,
Now, Person 1 going to update with his processed data. when updating a data, It will check the version/checksum. Version is 2, Person1's ver is 1, The version looks mismatch so there is a conflicts, If it mismatch, Then it will discard person 1 changes and do the operation again as same,
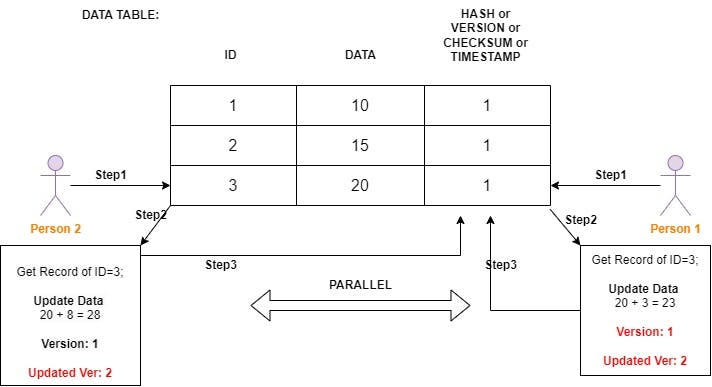
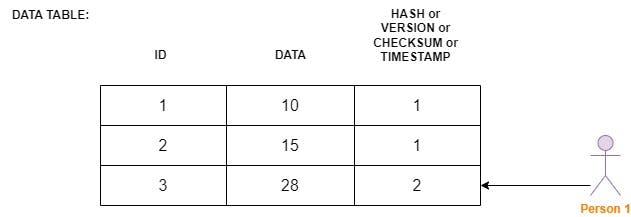
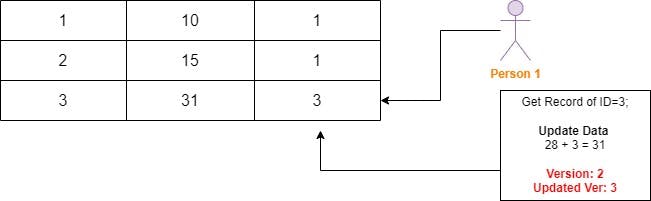
In Pessimistic Lock, We completely lock the specific row that the person 1 is trying to update. Person 2 cannot able to access the row, Once the person 1 updated his changes, Person 2 is allowed to do the necessory changes now.
In summary, an optimistic lock always allows the concurrent update, but a pessimistic lock does not. It doesn't mean that, we have to always use an optimistic lock. It depends on the use cases. When it comes to the distributed system, Optimistic Lock does a good performance.
The general rule of thumb:
Few conflicts -> Optimistic lock
More conflicts -> Pessimistic lock
Distributed Locking
More Conflicts between concurrent updates can be avoided by using the pessimistic lock. But In the concurrent system or distributed environment, We have to acquire a lock on the data element before performing any operations on it. There are various locking mechanism available that follows,
Apache ZooKeeper
Consul
Spring Integration
Spring Data Redis
Spring Cloud ZooKeeper & etc.,
These are some examples of how you can implement a distributed lock mechanism. Each of these solutions has its own features, performance characteristics, and integration requirements. When implementing a distributed lock mechanism using an external dependency, it's important to carefully consider factors such as fault tolerance, and scalability.
We are going to implement spring distributed lock. Since I'm working on the spring ecosystem.
Implementation of Spring Distributed Lock
Spring Integration is a module within the Spring framework that provides support for integrating different components and systems in a distributed environment. It offers a feature called the LockRegistry that helps implement distributed locking.
Dependencies for Spring Integration Lock:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-integration</artifactId>
</dependency>
- If you are using
JDBC, import the following:
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
The JDBC version of the distributed lock needs the database to have some tables and indexes set up in order to work. If you do not set these up the first time you attempt to obtain the lock, a JDBC Exception will be thrown. The current collection of SQL files for this can be found in the Spring Integration JDBC GitHub repo.
Create Lock Registery in configuration class: Imagine you have multiple nodes in your system, and each node needs to acquire a lock before accessing a shared resource. The
LockRegistryprovides a common interface that all nodes can use to acquire and release locks./** * Spring Distributed Lock - To avoid same data on the database */ @Bean public DefaultLockRepository DefaultLockRepository( @Qualifier("mySqlDataSource") DataSource dataSource){ return new DefaultLockRepository(dataSource); } /** * An ExpirableLockRegistry using a shared database to co-ordinate the locks. */ @Bean public JdbcLockRegistry jdbcLockRegistry(LockRepository lockRepository){ return new JdbcLockRegistry(lockRepository); }SetUp Controller and SetUp Services
@RestController @RequestMapping("/") @RequiredArgsConstructor public class LockController { public final LockService lockService; @PutMapping("/lock") public String lock(){ return lockService.lock(); } }@Service @RequiredArgsConstructor public class LockServiceImpl implements LockService { // If key is unique would be better. private static final String MY_LOCK_KEY = "someLockKey"; private static final int TRY_LOCK_WAIT_MIN = 2; public final LockRegistry lockRegistry; public DataDAO dataDAO; @Autowired public LockServiceImpl(JdbcLockRegistry lockRegistry, DataDAO dataDAO) { this.lockRegistry = lockRegistry; this.dataDAO = dataDAO; } @Override public String lock() { String returnVal = null; var lock = lockRegistry.obtain(MY_LOCK_KEY); try { if (lock.tryLock(TRY_LOCK_WAIT_MIN, TimeUnit.MINUTES)) { returnVal = "jdbc lock successful"; int rowId = 3; Datas datas = dataDAO.findById(rowId); datas.setData(datas.getData() + 8); datas.setVersion(datas.getVersion() + 1); dataDAO.updateDatas(datas); } else { returnVal = "jdbc lock unsuccessful"; } } catch (Exception e) { e.printStackTrace(); } finally { lock.unlock(); } return returnVal; } }
lock = lockRegistry.obtain(MY_LOCK_KEY). Obtains the specific lock we want from the database.
lock.tryLock(). Locks up the lock object. It stops other instances from processing what we want to process.
lock.unlock(). Unlocks the lock to prevent a deadlock.
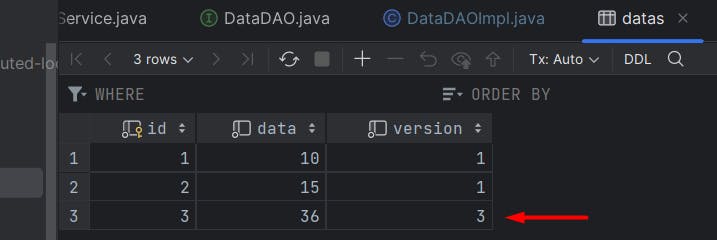
After this start the application and call the endpoint,
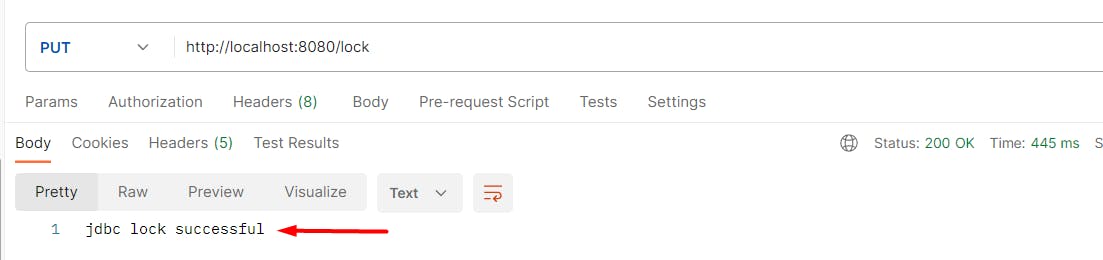
On the data table, Data got updated successfully.
Conclusion
In concurrent and distributed systems, choosing the right locking mechanism is crucial for maintaining data consistency and enabling efficient resource access. Pessimistic and optimistic locking offer different trade-offs and considerations. Additionally, distributed locking mechanisms provide ways to coordinate locks across multiple nodes or machines. By understanding these concepts and evaluating their implications, developers can make informed decisions when designing systems in distributed environments.
Source code:
References and Further Reading:
https://docs.oracle.com/cd/B14099_19/web.1012/b15901/dataaccs008.htm
How To Implement a Spring Distributed Lock | VMware Tanzu Developer Center
Happy coding...!